科学研究工作人员近期看到了依靠储存库劫持的状况十分广泛,这是一个掩藏的漏洞,容许所有人在客户变更登录名的情形下劫持储存库。这一漏洞类似子域名接手,利用起來非常容易,而且会造成远程控制编码引入。在剖析了这一漏洞的开源项目并归纳了检索他们的依赖关系图后,科学研究工作人员看到有超出70000个开源项目遭受危害,这包含来源于Google、GitHub、Facebook等企业的时兴新项目和架构。为了更好地改善这一漏洞,请保证你的新项目不依赖于GitHub的立即URL或应用依赖关系锁住文档和版本固定不动。

什么叫Repo Jacking?
依靠储存库劫持(别名“Repo Jacking”)是供应链管理上一个不为人知的漏洞,在理念上类似二级域名接手,危害超出7万只开源项目,危害从web框架到数字货币的任何实际操作。这一漏洞利用起來很不易,会造成远程控制编码引入,并危害来源于Google、GitHub、Facebook、Kubernetes、NodeJS、Amazon等企业的重点项目。科学研究员工在近期的一次主题活动中初次发觉这一漏洞后,就想要知道这一漏洞有多广泛,因此就对全部开源项目开展了递归法剖析,結果发觉它十分广泛。
什么目标易受Repo Jacking进攻?
每一个编译程序取决于GitHub储存库动态性链接代码的新项目都有可能遭受进攻,但是进攻要取得成功,必须考虑下列2个标准:
- 你的编码必须直接引用GitHub储存库(通常做为依赖关系)。
- 储存库的使用者必须变更/删掉它们的登录名。
当连接的储存库使用者变更其登录名时,所有人都能够马上再次申请注册该登录名。这代表着,一切连接回初始储存库URL的新项目如今都非常容易遭受依靠劫持的远程控制编码引入的进攻。故意网络攻击可以申请注册旧的GitHub登录名,再次建立储存库,并运用它向依靠它的其他新项目给予恶意程序。
即使取决于GitHub储存库的新项目如今还不易遭到进攻,但假如在其中一个依赖关系的使用者变更了他俩的登录名,那麼该新项目和别的取决于该旧连接的新项目便会遭受repo jacking的进攻。当储存库变更部位时,很有可能会产生某类警示,例如“404 -找不到储存库”之类的漏洞,但其实沒有。除此之外,Github的一项小作用(储存库跳转)使此漏洞显著更为风险。
“储存库跳转”使进攻更为比较严重
当GitHub客户变更储存库的命名或登录名时,GitHub设定了一个从旧URL到新URL的跳转,这类跳转与此同时适用HTTP和Git要求。当客户变更其登录名、传送储存库或重新命名储存库时,便会建立此跳转。这儿的漏洞是,假如再次建立初始储存库(在本例中为“twitter/bootstrap”),跳转将终断,并将你发送至创好的储存库。
实例情景
连接https://github.com/twitter/bootstrap偏向资料库“twitter/bootstrap”,但其实会将你跳转到“twbs/bootstrap”资料库。
假如Twitter变更了他俩的GitHub登录名,那麼所有人都能够再次申请注册它,再次建立一个名叫“bootstrap”的资料库,一切对https://github.com/twitter/bootstrap的新要求都将进到创好的资料库。
一切取决于https://github.com/twitter/bootstrap的新项目如今都将逐渐从这一新储存库载入编码。
跳转是一个便捷的作用,因为它代表着如果你重新命名你的账号时连接不容易马上终断。但这也代表着你的新项目很有可能在悄无声息中越来越非常容易遭受Repo Jacking的进攻。从你的方面看来,啥都没有更改,你的编码编译程序依然是一样的,一切都依照它应当的方法工作中。可是,你的新项目如今非常容易遭受远程控制编码引入的进攻,并且你并不了解。
三种劫持情景
更具体地说,在技术上讲,有三种不一样的形式可以使储存库越来越可以被劫持:
- GitHub客户重新命名其账号。这也是储存库可劫持的最普遍方法,由于客户重新命名其账号并不少见,而且在客户重新命名账号后,因为储存库跳转,一切都是会按预估开展。
- Github客户将其储存库迁移到另一个客户或机构,随后删掉其账号。客户迁移储存库时,将创建跳转,并根据删掉其客户来开启它,使其被所有人劫持。
- 客户删掉其账号。这也是三者中危害较小的,由于从初始客户删掉账号的那一刻起,一切引入该账号的工程在试着获得储存库时都是会逐渐发生漏洞。
留意:在客户删掉账号和新项目试着获得储存库中间,有几回网络攻击再次申请注册已删除的登录名,详细信息请点此。
GitHub的回复
在公布文中以前,科学研究工作人员已与GitHub联络,她们表明尽管这是一个已经知道漏洞,可是她们现阶段未有一切方案来变更跳转或登录名器重的方法。她们仅仅根据严禁再次申请注册造成删掉一周以内具备100个以上新拷贝的储存库名字来为一些受大家喜爱的储存库带来了一些减轻此问题的方式,如下所示上述。这的确带来了一定水平的维护,但并不是万无一失的解决方法,由于很多较小的储存库不符此规范,但仍旧可以为时兴新项目所依靠。
这儿的压根漏洞并不是GitHub容许跳转和登录名器重,反而是开发者从来不可靠的部位获取编码。GitHub没法监管这些出于意外目地应用其业务的开发者。有很多可以用的包管理工具(实际上,GitHub本身就有一个)用以处理远程控制编码依靠漏洞,开发者有义务保证她们从安全性部位载入编码。
漏洞危害范畴
漏洞危害范畴有多大,事实上,挑选全部开放源码新项目,编译程序他们的依赖关系,寻找全部可被劫持的储存库,并搭建易受攻击的储存库的依赖关系图并不易。

流程1:数据采集
对开源项目开展规模性剖析时,最艰难的部位之一是原始数据采集。为全部开源项目寻找一个全新的、精确的、非常容易检索的数据库索引是很不便的。科学研究工作人员关键应用2个数据开展剖析:
(1) GitHub主题活动数据信息
这也是由Github自身带来的,是一个较大的数据,包含超出280万只储存库,及其两者的全部文档和內容,全部数据的內容超出3TB。便捷的是,它被代管为谷歌云服务平台(GCP)上的一个公共性BigQuery数据,这代表着科学研究工作人员可以应用BigQuery从GCP自身内部结构在全部数据上运作SQL指令,而不用免费下载全部3TB文档。
为了更好地具体实行检索,科学研究工作人员转化成了一个正则,用以捕获一切Github URL或别的常用的Github依靠连接文件格式,如Github:username/reponame。应用这一正则,科学研究工作人员可以为包括对GitHub连接的引入的每一个文档获取储存库、文件夹名称和档案內容。这将科学研究员工的检索室内空间从3TB变小到更便于管控的4GB。通过过虑的数据包含400万只与众不同的GitHub连接和超出70万只不一样的GitHub客户。
(2) libraries.io
libraries.io是一个开源项目,致力于将来源于众多不一样装包程序管理器的全部依靠汇聚成一个相近数据图表的数据。这也是让人惊异的,因为它不但为科学研究工作人员完成了联接哪些依靠哪些的全部繁杂工作中,并且它还带来了全部数据可供免费下。未缩小时,该数据超出100GB,但可以立即读取到数据库系统中,便于于解决。
科学研究工作人员应用这两个数据是很重要的,由于每一个数据善于不一样的事儿。“Github主题活动数据信息”数据容许科学研究工作人员寻找储存库文件引入的每一个很有可能的Github连接,即使它沒有被用在显著的地区,例如包管理工具明细中。一些最有趣的发现并不一定是同时的编码依靠,科学研究工作人员常常发觉,在bash脚本中同时应用Github url来拷贝储存库或docker印象,这种印象将在搭建时从Github获取储存库。
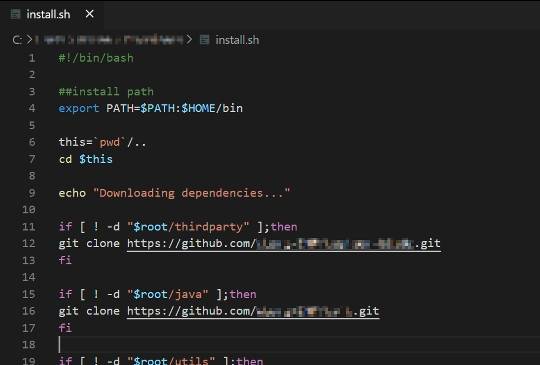
实例安裝脚本制作;所有人可以申请注册GitHub的连接
另一个普遍的发觉是可劫持的储存库做为Git子控制模块,这也是规范依靠剖析有可能会忽视的。
另一方面,“libraries.io”数据是一个早已清除、过虑和恢复出厂设置的数据,它使大家可以搭建依赖图并轻轻松松评定此漏洞的丰富性。根据这种数据,我们可以更全方位地掌握此漏洞对开源项目的整体危害。
流程2:清除
搜集了全部这种信息后,科学研究员工必须对它进行清除和规范性,这也是一项工作量非常大的工作中,由于科学研究员工必须考虑到每一个软件包管理工具的不一样文件格式。除此之外,科学研究工作人员期待删掉全部事实上沒有做为依赖关系应用的连接。这种连接中有很多是在注解中采用的,例如//code inspired from github.com/username/reponame,或是在文本文档文本文件中。因为分析工作人员关键关注编码引入的概率,因此分析工作人员删除了编码不容易立即采用的其他內容。这就给科学研究工作人员留有了高于200万只与众不同的GitHub连接,这种连接被文档以令人难忘的方法引入。
流程3:可劫持的登录名
如今科学研究工作人员拥有一个立即取决于GitHub连接的清楚新项目目录,科学研究员工必须找出现阶段没有注册的客户。到现在为止,科学研究工作人员有大概650k个Github登录名必须梳理。应用GitHub API,科学研究工作人员可以查验登录名是不是存有,但科研员工的网速限制在每钟头5000个要求,这代表着查验全部登录名要花5天以上的時间。根据一些精妙的逻辑关系和GitHub GraphQL API,科学研究工作人员可以将扫描仪全部650k客户的时长减少到2个小时多一点。
那麼,結果怎么呢?科学研究工作人员发觉,科学研究工作人员搜集的登录名中有7%(约50k)是没有注册的。老实巴交说,科学研究工作人员想不到这一数据会那么高。科学研究工作人员觉得仅有还不到1%的登录名是可以遭劫持的。显而易见,大家对自身的登录名觉得厌烦的水平远远地高于预估。
流程4:易受攻击的项目
一旦研究人员拥有全部很有可能遭劫持的登录名,系统漏洞就仅仅对研究人员的数据开展反方向检索,每一个项目都依赖于一个登录名所具有的储存库。通过进一步的过滤系统和清除乱报后,研究人员发觉一共有18000个项目立即非常容易遭受库挟持的进攻。这种项目在GitHub上一共有超出50千颗星辰,而且包含了来源于一些较大的开源系统机构的几乎每一种语言表达的项目。
仅这一数据就让人害怕,可是当代代码库并并不是运作在单独储存库文件的巨大总体。反过来,他们在功用上依赖于很多别的项目。这针对可扩展性和可器重性而言是有效的,但这代表着单独时兴依赖关系中的缺陷会很大地影响依赖关系链上的很多项目。事实上,一切依赖于18000个立即易受攻击项目的项目自身也是易受攻击的。
流程5:依赖感剖析
如今研究人员就拥有一个立即易受攻击的项目目录,将其与之前的数据一起用以实行依赖关系图污渍检索,并寻找每一个依靠其供应链管理中易受攻击的仓储的项目。在这里剖析中,研究人员包含了一般的依赖关系和不太显著的依赖关系,例如开发设计依赖关系或没有在主包明细文档中的依赖关系。假如这种輔助依赖关系中的一个非常容易遭受repo sniping的影响,则影响很有可能要更长的时间段能够在依赖关系链上散播,由于这类影响很有可能仅在开发设计人员公布最新版本时才会产生。充分考虑这一点,研究人员开始了进攻剖析。
因为易受攻击项目的数目很有可能会呈指数级增长,研究人员会逐渐开展解析xml。在每一次传送环节中,研究人员都手动式查验結果,并删掉一切显著的乱报,以降到最低系统漏洞散播,并保证研究人员的效果不容易被乱报所遮盖。
通过5次解析xml后,研究人员迫不得已慢下来。由于在第5轮以前,数据信息的提高全是可以预测分析的,且每一轮检索都耗费了有效的時间,但当研究人员开展第6轮遍历经,数据信息逐渐不能操纵地提高。看一下第五轮的結果,缘故就明白了,研究人员早已构建了好几个大中型的基本架构,并被许许多多的别的项目所依靠。这足够让研究人员了解这一系统漏洞的影响。目前为止,研究人员早已看到了超出7万只受影响的项目,在其中GitHub大牌明星项目数量超出150万只,这比GitHub前8大信息库加在一起还需要多。尽管这难以精准考量,但研究人员可能这种项目的总注册量最少有200万。
受影响的项目包含来源于大中型机构(例如Google,GitHub,Facebook,Kubernetes,NodeJS,Amazon等)的储存库。从中小型普通用户项目到不计其数个机构应用的时兴Web架构,一切都遭受影响。有意思的是,它会影响许多不一样种类的手机软件。研究人员发觉了易受攻击的路由器固件、手机游戏、数据加密钱夹、挪动APP和很多别的与众不同的项目。
减轻对策
- 不必立即连接到GitHub储存库。
- 版本号固定不动和锁住文档。
文中翻譯自:https://blog.securityinnovation.com/repo-jacking-exploiting-the-dependency-supply-chain